Pythonプログラミング(クラスタリング)
このページは、クラスタリングのアルゴリズムとしてDBSCAN(Density-Based Spatial Clustering of Applications with Noise)法を紹介する。
$k$-means 法の限界と密度への着目
前のページで扱った $k$-means 法は、各クラスタが重心の周りにガウス分布的に広がっていることを暗に仮定していた。 これに対し DBSCAN は、点の「混み具合(密度)」だけに着目することで、 任意の形状のクラスタを検出でき、かつどのクラスタにも属さない外れ値(ノイズ)を自然に扱える点が特徴である。
$k$-means 法では、各データ点を「最も近い重心」に割り当てる。 この仕組みは、クラスタが概ね球状(等方的なガウス分布)に分布している場合にはうまく機能するが、 次のような場合には意図した結果が得られない:
- クラスタが細長い・曲がっている・入れ子になっているなど、非球状の形状をもつ場合
- クラスタ数 $k$ をあらかじめ指定できない場合
- 明らかな外れ値(ノイズ)が含まれ、それらを無理にどこかのクラスタへ含めたくない場合
DBSCAN は「クラスタとは、点が密に集まっている領域である」という素朴な発想に基づく。 密な領域が途切れずにつながっている限り、その形が三日月型であれ渦巻き型であれ、一つのクラスタとみなす。
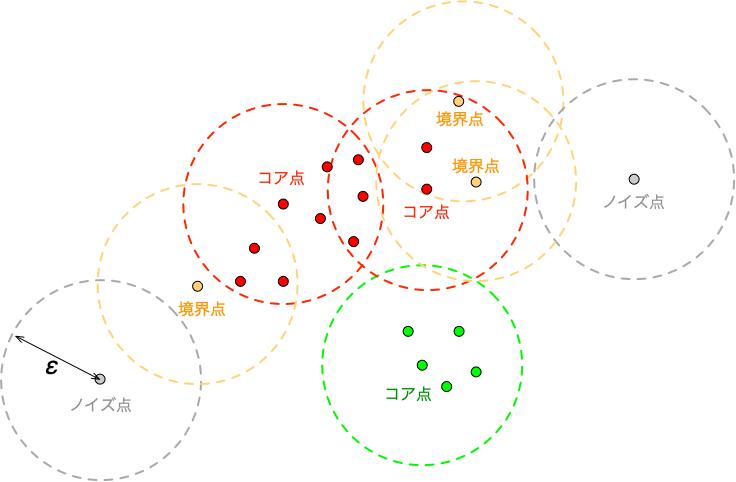
2つのパラメータと3種類の点
DBSCAN は、次の2つのパラメータによって「密」の基準を定める:
- $\varepsilon$(イプシロン):ある点の「近傍」とみなす半径。
- $\mathit{MinPts}$(最小点数):その近傍に最低限含まれるべき点の数。
ある点 $\boldsymbol{x}$ の $\varepsilon$-近傍を、距離 $d(\cdot,\cdot)$ を用いて $$ N_\varepsilon(\boldsymbol{x}) = \{\, \boldsymbol{y} \mid d(\boldsymbol{x}, \boldsymbol{y}) \le \varepsilon \,\} $$ と定義する。これに基づき、各データ点は次の3種類に分類される:
- コア点(core point):$\varepsilon$-近傍に $\mathit{MinPts}$ 個以上の点を含む点。 すなわち $|N_\varepsilon(\boldsymbol{x})| \ge \mathit{MinPts}$。混雑領域の内部にあたる。
- 境界点(border point):自身はコア点ではないが、あるコア点の $\varepsilon$-近傍に含まれる点。クラスタの「ふち」にあたる。
- ノイズ点(noise point):コア点でも境界点でもない点。どのクラスタにも属さない外れ値とみなす。
$\varepsilon$ の円の中に $\mathit{MinPts}$ 個以上の点があればコア点。図は $\mathit{MinPts}=5$ の例。
密度到達可能性とクラスタの定義
クラスタの「つながり」を定義するために、いくつかの関係を導入する。
- 直接到達可能(directly density-reachable): 点 $\boldsymbol{q}$ がコア点であり、かつ $\boldsymbol{p} \in N_\varepsilon(\boldsymbol{q})$ であるとき、 $\boldsymbol{p}$ は $\boldsymbol{q}$ から直接到達可能であるという。
- 到達可能(density-reachable): 点列 $\boldsymbol{q} = \boldsymbol{o}_1, \boldsymbol{o}_2, \cdots, \boldsymbol{o}_m = \boldsymbol{p}$ が存在して、 各 $\boldsymbol{o}_{j+1}$ が $\boldsymbol{o}_j$ から直接到達可能であるとき、 $\boldsymbol{p}$ は $\boldsymbol{q}$ から到達可能であるという(コア点の連鎖でつながっている状態)。
- 密度連結(density-connected): あるコア点 $\boldsymbol{o}$ から $\boldsymbol{p}$ と $\boldsymbol{q}$ の両方が到達可能であるとき、 $\boldsymbol{p}$ と $\boldsymbol{q}$ は密度連結であるという。
DBSCAN におけるクラスタとは、互いに密度連結な点の極大集合として定義される。 コア点が数珠つなぎに連結することでクラスタが「成長」するため、 途中で曲がっていても枝分かれしていても、密度が途切れない限り一つのクラスタとなる。
DBSCAN のアルゴリズム
以上を踏まえると、アルゴリズムは次のように記述できる。 全ての点を「未訪問」とした状態から始める。
- 未訪問の点 $\boldsymbol{x}$ を一つ選び、「訪問済み」とする。
- $\boldsymbol{x}$ の $\varepsilon$-近傍 $N_\varepsilon(\boldsymbol{x})$ を求める。
- $|N_\varepsilon(\boldsymbol{x})| \lt \mathit{MinPts}$ ならば、$\boldsymbol{x}$ をノイズと仮にラベル付けする (後に別のコア点の近傍として境界点へ変わる場合がある)。
- $|N_\varepsilon(\boldsymbol{x})| \ge \mathit{MinPts}$ ならば、$\boldsymbol{x}$ はコア点である。 新しいクラスタ $C$ を作り、以下の拡張を行う。
- クラスタの拡張:$N_\varepsilon(\boldsymbol{x})$ に含まれる点を順に処理する。
近傍の各点 $\boldsymbol{y}$ について:
- $\boldsymbol{y}$ が未訪問なら訪問済みとし、その $\varepsilon$-近傍を調べる。 $\boldsymbol{y}$ もコア点であれば($|N_\varepsilon(\boldsymbol{y})| \ge \mathit{MinPts}$)、 その近傍点を処理対象に追加する(連鎖的に拡張)。
- $\boldsymbol{y}$ がまだどのクラスタにも属していなければ、クラスタ $C$ に加える。
- 処理対象がなくなったらクラスタ $C$ の確定。1へ戻り、未訪問の点がなくなるまで繰り返す。
最終的に、どのクラスタにも加えられなかった点がノイズ(外れ値)として残る。 $k$-means と異なり、クラスタ数は事前に与えるのではなく、データの密度構造から自動的に決まることに注意したい。
素朴な実装例
上記のアルゴリズムを、ライブラリを使わずそのまま Python で記述した例を以下に示す。 データ生成の部分は前ページの $k$-means の例にならっている。
import numpy as np
import matplotlib.pyplot as plt
# --- パラメータ ---
eps = 7.0 # 近傍半径 ε
min_pts = 10 # 最小点数 MinPts
# --- データ点の生成 ---
x = np.empty((0,2))
sigma = [[20,0],[0,20]]
for ell in range(3):
# グループ毎の代表点
pc = np.random.uniform(low=-20, high=20, size=(2,))
xs = np.random.multivariate_normal(pc, sigma, 30)
x = np.concatenate([x,xs])
# --- DBSCAN 本体 ---
UNVISITED, NOISE = -2, -1
n = x.shape[0]
labels = np.full(n, UNVISITED) # 各点のクラスタ番号
cluster_id = -1
def neighbors(i):
d2 = ((x - x[i])**2).sum(axis=1)
return np.where(d2 <= eps**2)[0]
for i in range(n):
if labels[i] != UNVISITED:
continue
nb = neighbors(i)
if len(nb) < min_pts:
labels[i] = NOISE # 仮にノイズとする
continue
# コア点 → 新しいクラスタを開始
cluster_id += 1
labels[i] = cluster_id
seeds = list(nb)
k = 0
while k < len(seeds):
j = seeds[k]; k += 1
if labels[j] == NOISE:
labels[j] = cluster_id # ノイズ→境界点に昇格
if labels[j] != UNVISITED:
continue
labels[j] = cluster_id
nb_j = neighbors(j)
if len(nb_j) >= min_pts: # j もコア点なら連鎖拡張
seeds.extend(nb_j.tolist())
# --- 結果のプロット ---
cmap = plt.get_cmap("tab10")
for c in range(cluster_id + 1):
pts = x[labels == c]
plt.scatter(pts[:, 0], pts[:, 1], color=cmap(c))
noise = x[labels == NOISE]
plt.scatter(noise[:, 0], noise[:, 1], color="lightgray", marker="x", label="noise")
plt.legend(); plt.grid(True)
plt.show()
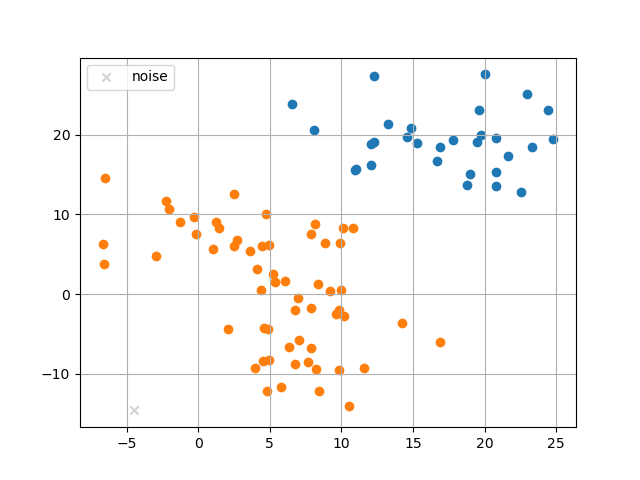
以下が上記のコードの実行例である。色付きの点が各クラスタ、灰色の × がノイズ点。
neighbors(i) は毎回すべての点との距離を計算しているため、
点の数 $N$ に対して計算量は $O(N^2)$ となる。
大規模データでは、KD木などの空間索引を使って近傍探索を高速化するのが一般的である。
scikit-learn の使用
実用上は scikit-learn の DBSCAN クラスを使うのが簡単である。
前ページの KMeans の例と同じ流儀で書ける:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import DBSCAN
# データ点 x は上と同様に生成しておく
db = DBSCAN(eps=7.0, min_samples=10)
g = db.fit_predict(x) # ノイズ点には -1 が入る
cmap = plt.get_cmap("tab10")
for c in set(g):
pts = x[g == c]
color = "lightgray" if c == -1 else cmap(c)
plt.scatter(pts[:, 0], pts[:, 1], color=color)
plt.grid(True)
plt.show()
fit_predict(データ配列) は各点のクラスタ番号の配列を返し、
ノイズと判定された点には -1 が割り当てられる。
 練習:パラメータの影響
練習:パラメータの影響
$\varepsilon$ と $\mathit{MinPts}$ の値を変えると、検出されるクラスタ数やノイズ点の数がどう変化するかを調べなさい。 特に、$\varepsilon$ を極端に小さく/大きくしたとき、結果がどうなるか考察しなさい。
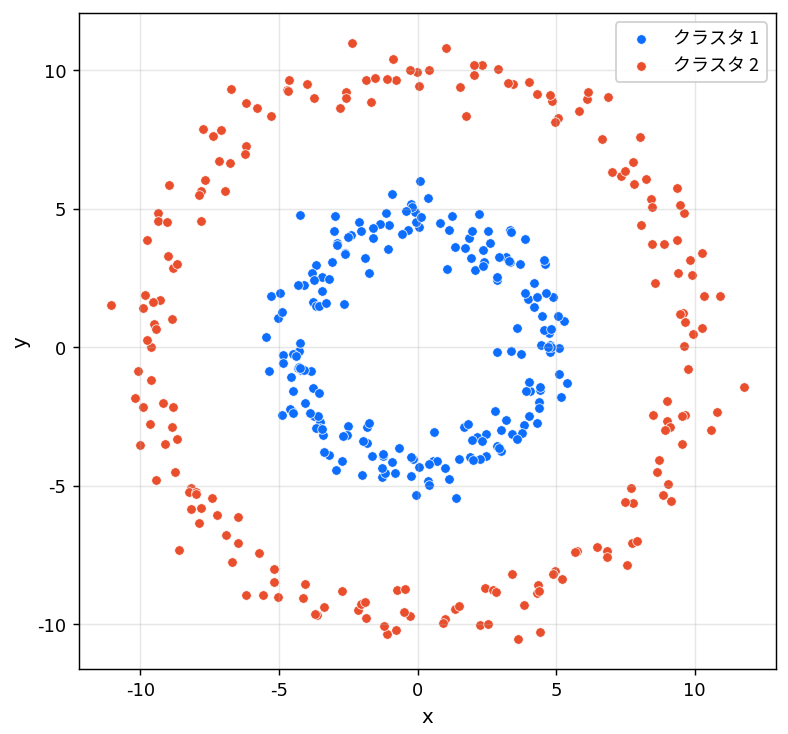
練習:k-means との比較
同心円状や三日月状のデータを生成し、$k$-means 法と DBSCAN の双方でクラスタリングして結果を比較しなさい。 それぞれがどのような形状のデータを得意/不得意とするか、図をもとに説明しなさい。
 解説: DBSCAN の限界と発展
解説: DBSCAN の限界と発展
DBSCAN は単一の $\varepsilon$ を全体に適用するため、 クラスタごとに密度が大きく異なるデータでは、すべてのクラスタを同時にうまく検出することが難しい (密なクラスタに合わせると疎なクラスタがノイズ扱いになり、その逆も起こる)。 この問題に対処するため、密度の階層構造を扱う HDBSCAN などの発展的手法が提案されている。